簡単に説明すると、AIは、本やWebの記事を山ほど読んで「この言葉の次は何が来やすいか」を覚えた文章予測マシンです。人のように“意味”を深く理解しているというより、過去の使われ方を手がかりに正しく言葉をつなげます。最新情報が要る場面では、必要に応じて検索で記事を取り込み、出所(URL・日付)も一緒に付けるよう指示することで、根拠付きの回答になります。つまり「予測で文章を作る」+「必要なら出典を添える」です。

Oct 19, 2025

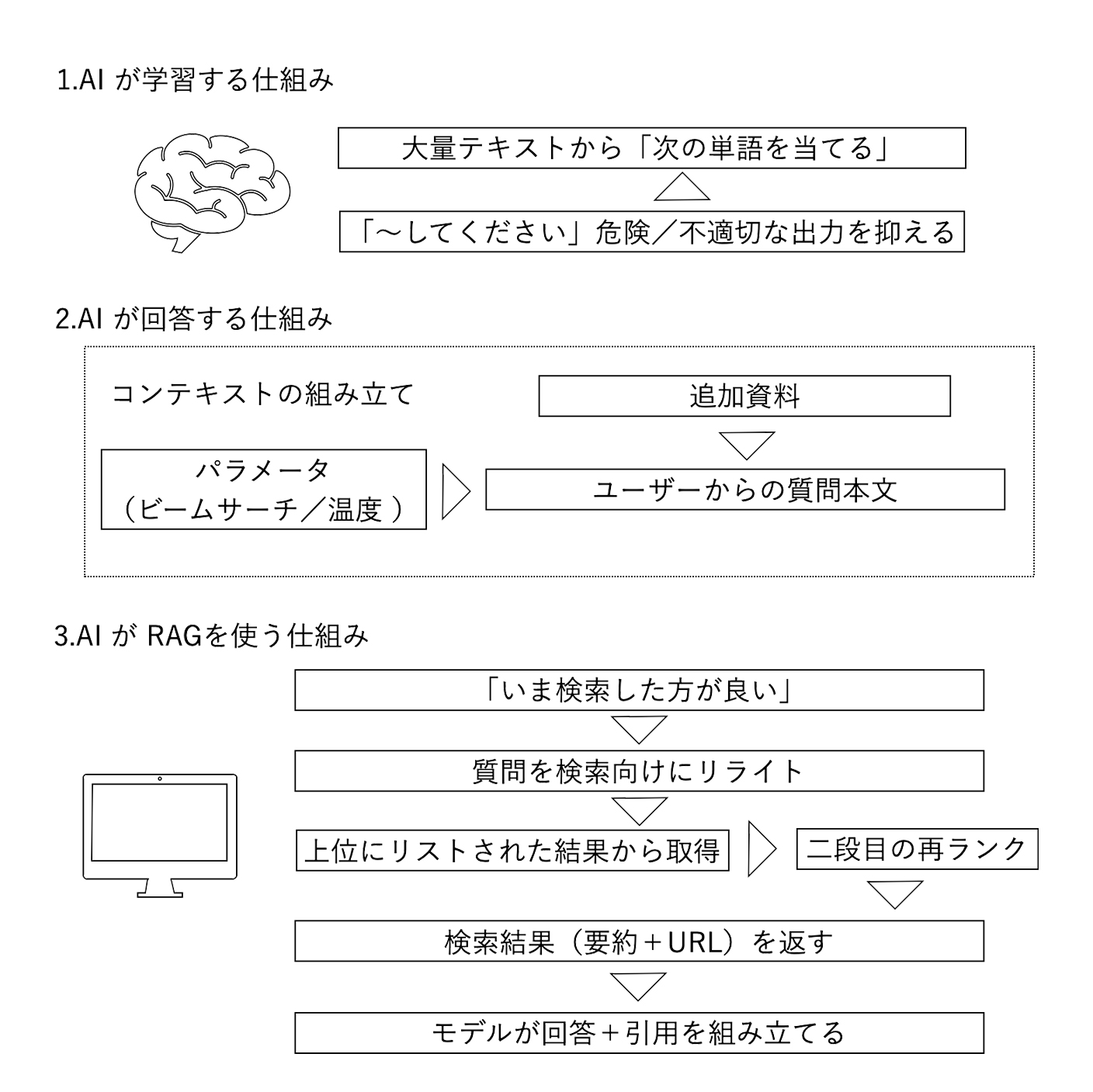
まずはベースとなる AI の構造についてです。事前学習と呼ばれている仕組みを導入します。文字列をトークン(サブワード単位)に分割するトークン化(tokenization)をします。そして、直前までのトークン列から次トークンの確率分布を出します(autoregressive LM)。さらに、文脈の中でどこに注意を向けるかを学ぶ仕組み(自己注意 self-attention)を入れて、単語/文をベクトルで表現し、意味が近いと近い位置に並べます(embedding)。
要するに、やっていることは、大量テキストから「次の単語を当てる」能力を鍛えているわけです。
AI が“理解している”と思われがちですが、言葉の意味の本質を理解しているわけではありません。そもそも理解しているかどうかを見極める方法を突き詰めていくと、言葉としてのアウトプットで検証するしかないわけですよね。言葉で伝えもらわなければ、理解しているのかを判断できないですよね。つまり、アウトプットに最適化された仕組みができると、理解しているとイコールとなるわけです。
人の理解との大きな違いは、感情の有無です。機械には感情はないので、どのようなことを認識して理解しても、動揺することはないというわけです。ただ、動揺しているかのような返事を返す仕組みにすれば、まるで感情があるかのように感じるというわけです。
次に、指示追従微調整(SFT)と呼ばれている「~してください」に素直に従うようにサンプルで微調整(Fine-tuning)と整合(Alignment)を行います。そのために RLHF と言われる「人の好みを反映する強化学習」と、危険/不適切な出力を抑えるルールやガードレールを入れます。
要するに、暴走を止める作業です。核兵器の作り方は教えないようにするといった制限を加えるわけです。
実運用では安全ポリシーやツール連携の調整が継続しますが、これで基礎性能は整います。
続いて、出来上がった AI がどのように動作するのかという話をします。内部で行われているのは大きく 3 つです。
2-1 コンテキストの組み立て
2-2 次単語予測の連鎖(デコード)
2-3 ツール利用(Tool Use / Function Calling)
コンテキストの組み立ては、ユーザーからの質問本文を受け取り、事前に設定されているモデルの役割や出力様式の指示(システム/デベロッパープロンプト)に従って、オーケストレーターや実装側がトークン上限を管理し、追加資料(後述の検索結果や社内ドキュメント要約など)を詰めて入力します。
入力されたコンテキストは、あらかじめ設定されているパラメータ(ビームサーチ/温度/トップ P など)によって多様性と一貫性の調整を行います。内部で複数回の推論ステップ(Chain of Thought/思考の連鎖)を経て、最終結論だけがアウトプットされます。
アウトプット時には、ツールで得た出典情報(URL/タイトル/発行日)を回答の中に差し込むよう指示されたプロンプトに従います。
このときに、モデルが「いま検索した方が良い」と判断すると、function calling と呼ばれる関数呼び出しが機能して、検索 API を呼ぶ関数出力を生成します。オーケストレーターが API を実行 → 検索結果(要約+URL)を返す → それを再びモデルに渡す → モデルが回答+引用を組み立てる、という流れとなります。
Function calling が実装された時にはニュースになるほど画期的でした。この機能の実装により、最新情報・根拠付き回答が可能となったわけです。Pretraining & Alignment が完了した AI は、完成時点までのデータしか知りません。例えば、OpenAIのケースでは、学習更新周期は非公開で、モデルごとに知識カットオフが異なるのでなんともいえませんが、RAG(Open AI はRAGとは言っていない)を使わなければ、単体ではオフラインなので昨日の天気すら答えられないわけです。
なお、function calling は外部検索や DB 照会などの“ツール”を呼ぶ仕組みであり、RAG(Retrieval-Augmented Generation)は“外部から得た情報で生成を補強する方式”です。RAG には Web 検索やベクトル DB 参照などが含まれます。
続いて、この RAG について説明します。ここでは「検索」に絞って説明します(※RAG 自体はベクトル DB 参照も含みます)。質問を検索向けにリライト(query rewrite)します。
要するに、ユーザー質問:「ASML の直近の決算は?」に対して、「ASML earnings Q3 2025 site:investors.asml.com」など複数案の質問を追加で生成します。
そして、指定された検索エンジンを使って(ChatGPT の場合には主にマイクロソフトの Bing)上位にリストされた結果から取得しに行きます。「何件取るか」は“検索 API の上限”+“運用ポリシー(精度×コスト×速度)”で決めます。仕様変更の可能性はありますが、例えば、Bing Web Search API:count のデフォルト=10、最大=50/offset でページネーションとなっています。同様に、Google Custom Search API:1 ページ=10 件固定(num 最大 10)。start でページを進める。API 全体で最大 100 件まで取得可能です。Brave Search API(Web):count 最大=20(offset でページング)。画像・動画は別上限。Perplexity Search API:max_results は 1~20、さらに各ページから抽出するトークン量を max_tokens_per_page で制御しています。
ここでポイントとなるのが、多く取りすぎると重複や品質低下があるということです。ただし、検索上位は入口になりやすい一方で、二段目の再ランクで一次情報や新情報が上位に来ることも多い点には留意が必要です。そもそも検索エンジンもユーザー志向のアルゴリズムなので、いかに良質の結果を返すかということを考えて設計されており、この思想そのものは、AI 検索でも全く同じです。
ただ、異なるのが、
第 1 段:トップ K=10~20 を検索 API で取得した後、
第 2 段:本文抽出→再ランク(BM25+埋め込み類似度+クロスエンコーダ)で上位 5~10 に絞る、
第 3 段:要約・検証しつつ、足りなければ追加ページ(offset/start で+10~20)を取得して、精度(precision)と網羅(recall)のバランスを取っている点です。
この動作は、「新製品の公式仕様」「決算の数値」のような一次情報系は少数精鋭(3~6 件)で十分、社会トピックや論争点は多め(20 件→再ランク→8~12 件読む)で矛盾チェック、といった具合に信頼度で可変させています。
要するに、人が今まで検索していた流れと同じことを機械がやっているわけです。人よりも段違いの速度で取得するので、効率的になるというわけです。
ざっくりですが、以上が AI 検索の仕組みです。この仕組みを頭の片隅に入れて LLMO に取り組むと、なぜこのようなタスクが重要なのかということの理解が早くなるかと思います。
Kyo42では、AI導入について無料相談を承っております。お気軽にお問合せください。



環境の変化に対応できた
企業だけが存続し成長する。